FRONT ROW
Amazon Returns Tracker
2022
The Problem
Our company provides logistical services, including reviewing and processing returns and resolving various issues by submitting Amazon Support Cases. There are multiple scenarios of return distribution and tracking, depending on whether it’s an FBA (Fulfilled By Amazon) or FBM (Fulfilled By Merchant) item, its condition and current Amazon status.
Currently, processing returns is a largely manual, time consuming procedure that requires back and forth interactions with Amazon Seller Central, the use of multiple tables in Spreadsheets, manual inputs and copying/pasting, with a high possibility of user making an error. The existing software only allows to manually input FBM data. It’s hard to keep track of all the information and steps, when the data is stored in multiple places.
How can we streamline the returns tracking process and increase its efficiency to accommodate for the company’s growing number of clients, and therefore returns?
UX Research
The focus of the research will be on thoroughly looking into the User Persona and their Task Flows and all possible Action Scenarios that the user might have to work with. Last but not the least, I am going to look into the Data that may available to us via Amazon APIs, in order to simplify user operations and reduce manual inputs.
User Persona

ALEX - Logistics Associate
Alex is a college student and a temporary employee of the logistics department. He received training to perform highly specific operations of processing Amazon returns when he was employed. He is unlikely to use these skills in the future, but for now he has to be very thorough, focused and operate with high precision to avoid any errors.
Behaviors: Orders return shipments from Amazon, receives boxes, opens them and reviews returned items to make a decision on disposal or restocking. Mails out the resellable items back to Amazon. Keeps track of returns all returned items by documenting returns and disposals in spreadsheets, or in our software for FBM items.
Needs and wants: Needs to operate quickly and with precision. Needs to adjust to the growing number of company clients, and therefore returns. Wants for the process to be easier and error proof, and require fewer manual operations.
Frustrations: It’s hard and tiring to keep track or return orders, shipment plans and products, considering the need to navigate between Amazon Seller Central, many spreadsheet tabs, and our internal software. Multiple operations involving copying and pasting numbers and manual inputs make errors likely to happen, so Alex is constantly worried and checks his inputs, which increases return processing time.
Task Flows
Item Distribution Details
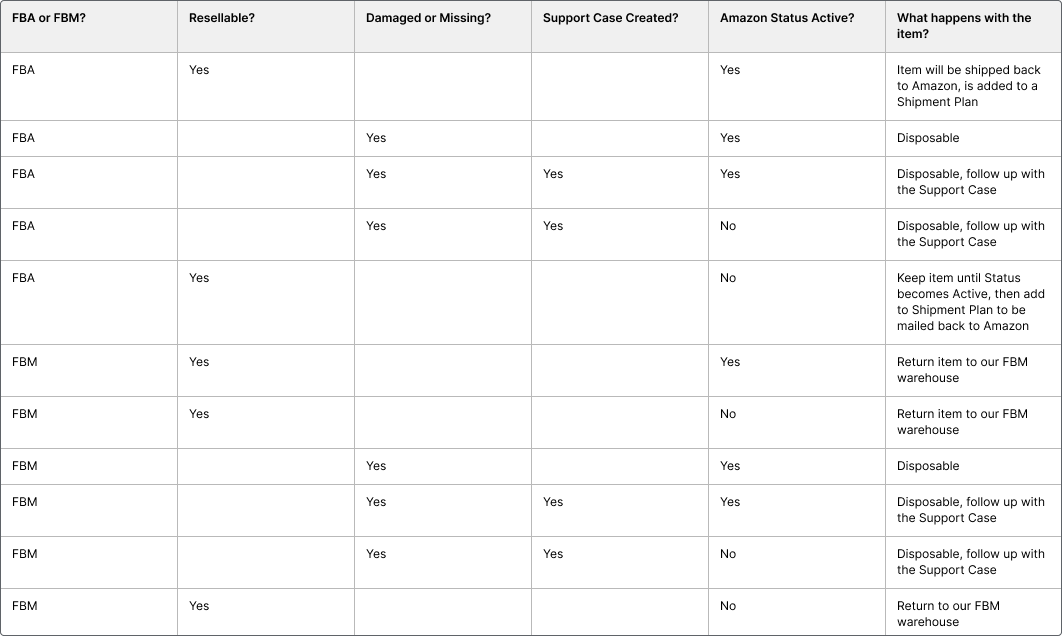
In order to build interfaces properly, it’s crucial to understand how the returned items are processed.
I looked into every possible scenario of item distribution.
The Solution
Create the following key functions:
Scanning return orders from Amazon;
Distributing return orders;
Creating Shipment Plans for mailing resellable items back to Amazon;
A system for storing all the data on the returns in the same place and managing previous returns.
Automate as many processes as possible by:
Introducing algorithms for item distribution into the system;
Using data pulled from Amazon APIs.
Information Architecture
Software structure and Data flows
Greyscale Prototypes for the Key Functions

Testing and Iterations
When we tested the interface by plugging numbers in the columns, it became clear that the inputs were ambiguous and didn’t help answer the question precisely:
How do we identify that we received the full number of the expected items but some of them is/are damaged, versus the order arrived incomplete?
Testing of the Return Order Distribution Interface
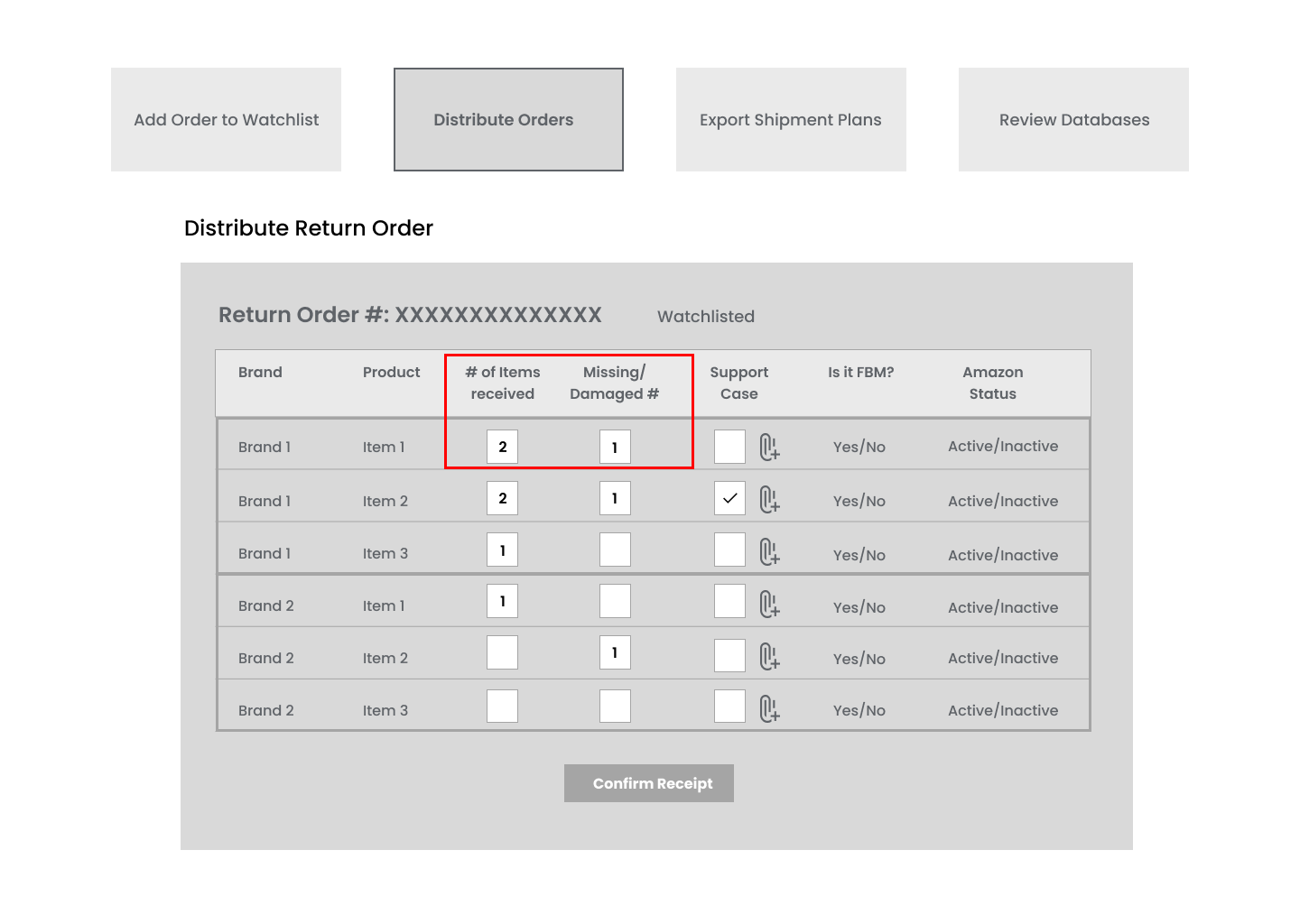
Iteration 1.
In order to avoid ambiguity, I separated the missing and damaged items into two columns. It seems to have helped a lot, but now we still have unanswered questions:
We are still not sure if the total number includes the missing items;
Which one is missing and which one is damaged, and for which of them the support case is created?
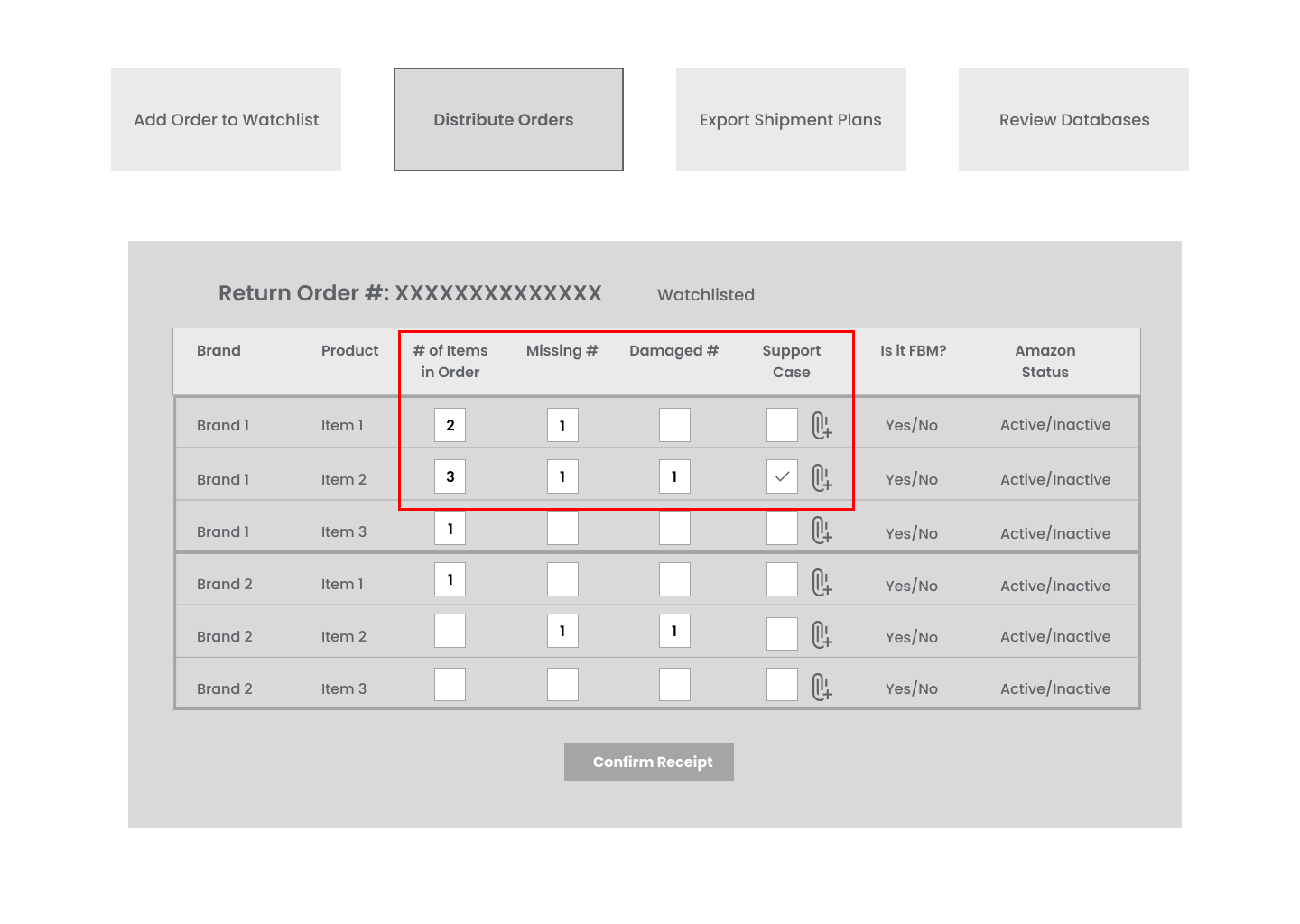
Iteration 2.
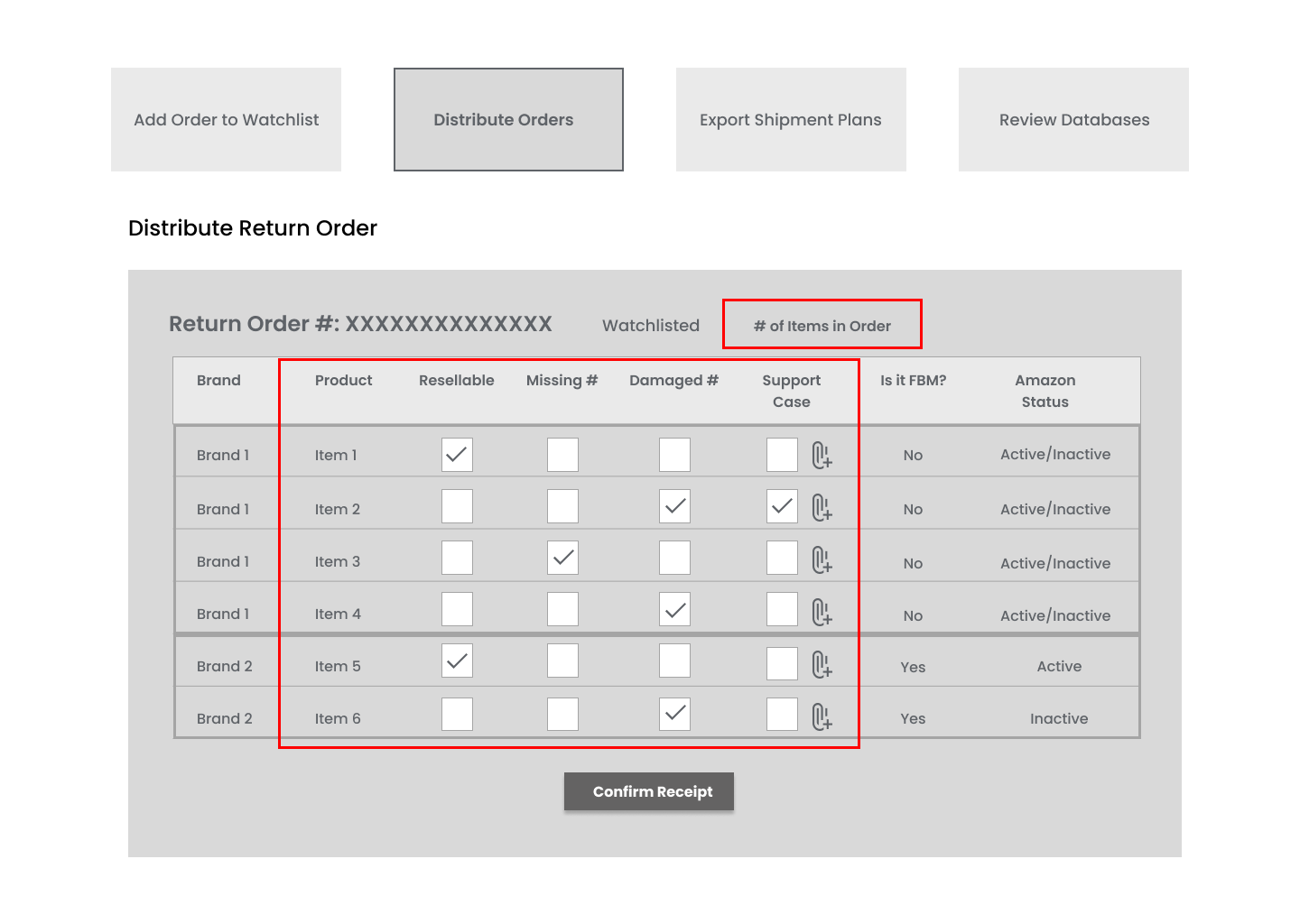
To make the inputs as clear as possible and organize the data better, I introduced the following changes:
Separate row for each individual item;
Separate columns for clear identification between Resellable, Missing and Damaged items, which would also help indicate for which one the support case was created;
The total number of items in the order is brough to the top for the reference.
Optimizing Adding to Watchlist Function
We looked into possibly simplifying the adding to watchlist procedure, and realized that since most often the orders are reviewed once a week, we can display orders for the past 7 days by default in a widget as opposed to the dropdown, and provide additional options in the dropdown filter. This will minimize the number of operations and speed up the process.
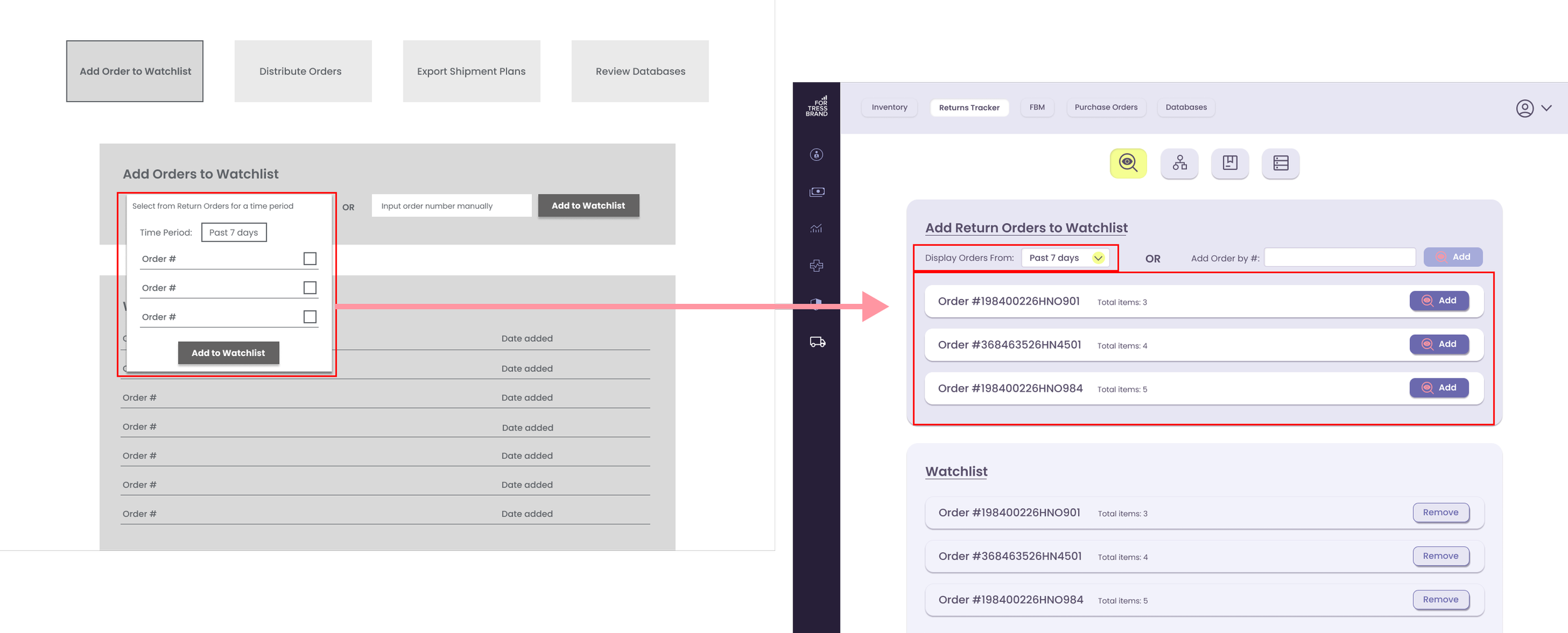
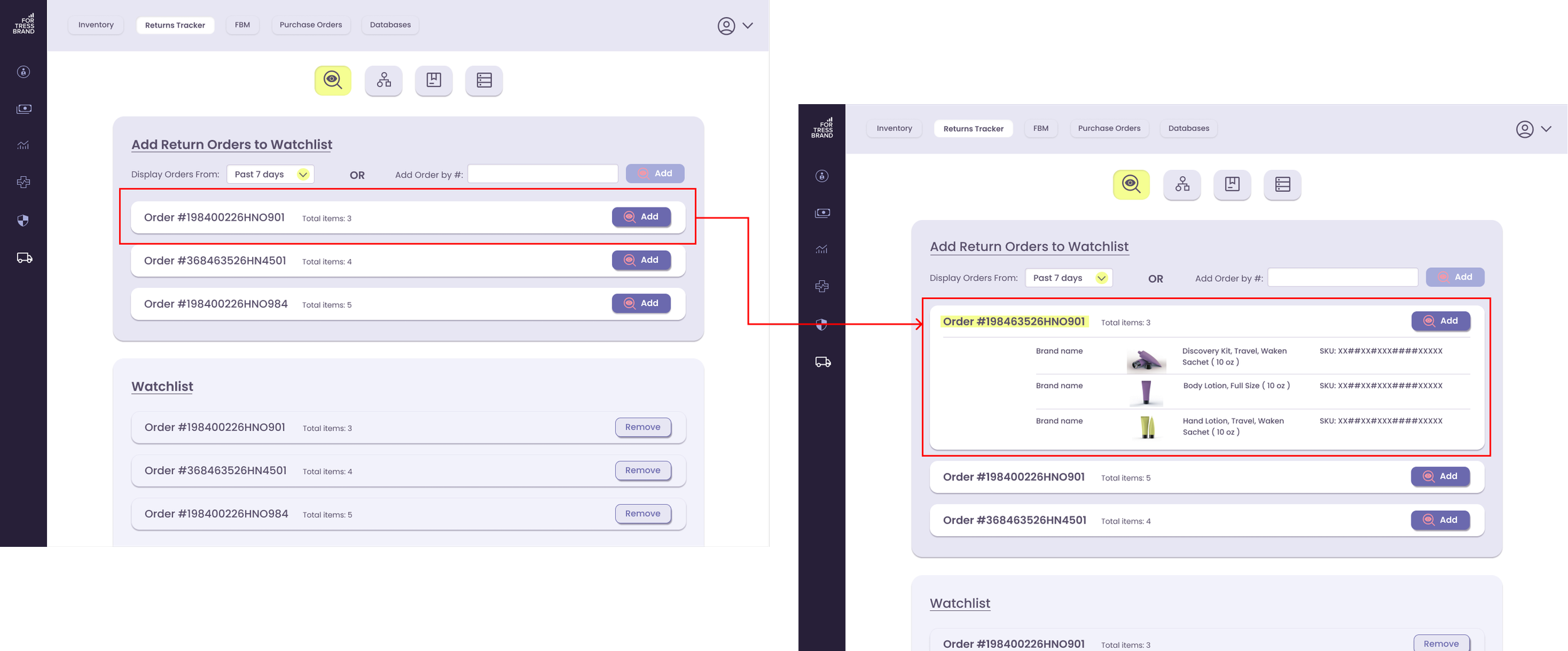
Additionally, displaying orders in a widget will allow user to easier review the contents of the order..
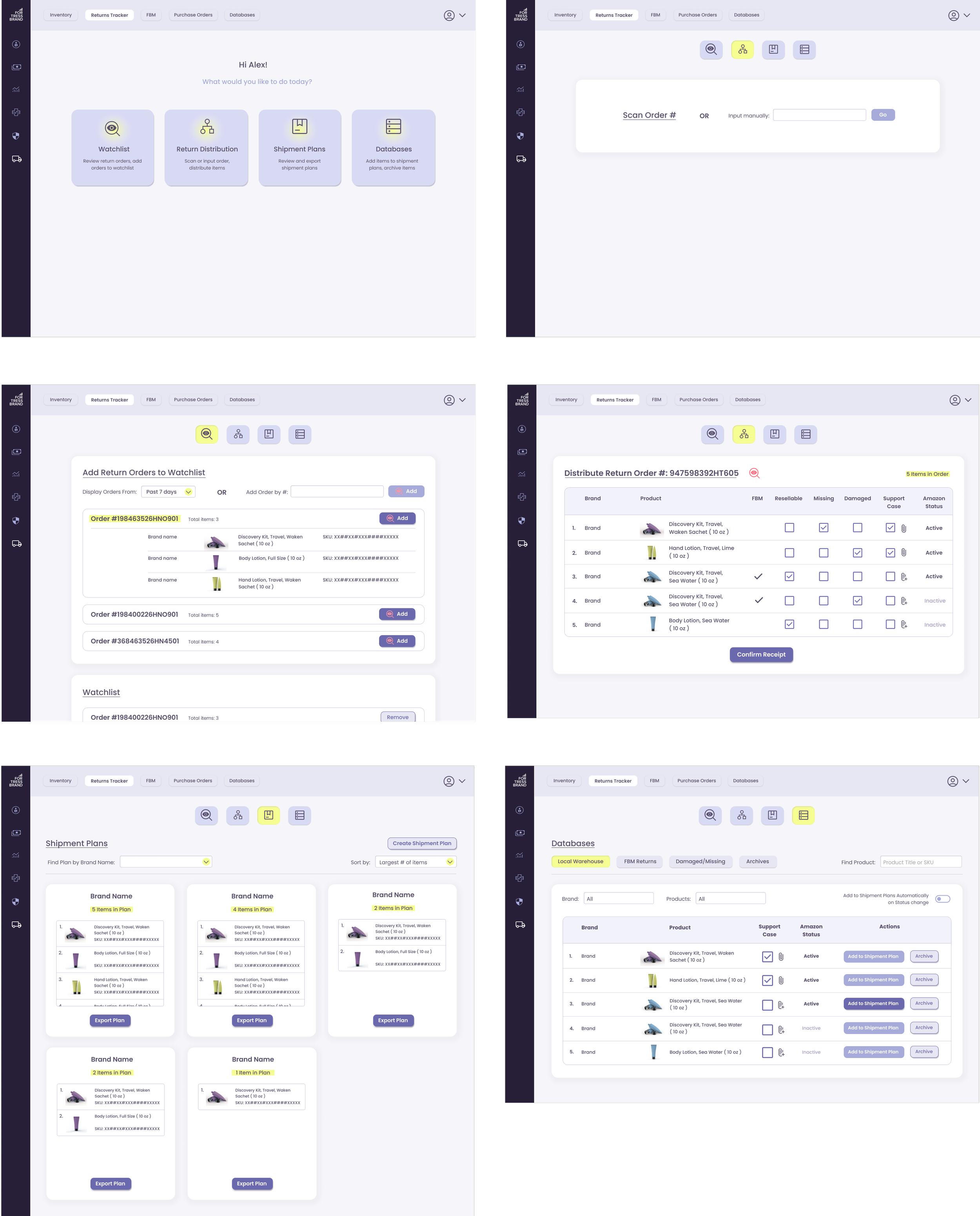
High Fidelity Prototype
The Outcome
Implementation of the Returns Tracking Software significantly improved the return processing by the following parameters:
Increased efficiency of the returns processing operations;
Reduced error rates;
User satisfaction.
An employee’s feedback:
“We use the software daily; it’s very clear, straightforward and easy to use. It helps us very much.”